「Unity ML-Agents 実践ゲームプログラミング v1.1対応版」の 2章の写経です。
今回、この書籍より新しい 「ML-Agents Release19 + unity 2021.3 + python3.8 on windows 11」 を使用している為、書籍に記載されるsample codeと異なる点があります。
create unity 3D core project & install mlagents to unity
先日のentryの「4. install mlagents to unity」から 「5-1. 学習の準備」を行って下さい。
ただし、「C:\Users\end0t\tmp\ml-agents_19\Project\Assets\ML-Agents」の コピーは不要です。
ML-Agents Release19 + unity 2021.3 + python3.8 on windows 11 の環境作成 - end0tknr's kipple - web写経開発

Main Camera の位置修正

Materialの作成
「Project欄 → Create → Material」から、以下の3色を作成して下さい。
| name | Main Maps→Albedo |
|---|---|
| Gray | RGB = 168,168,168 |
| Brown | RGB = 212,154,33 |
| Blue | RGB = 0,35,255 |


Floorの作成
「Hierarchy欄 → 3D Object → Plane」から、 Inspector欄で以下のように設定して下さい。


Targetの作成
「Hierarchy欄 → 3D Object → Cube」から、 Inspector欄で以下のように設定して下さい。


Sphere ( RollerAgent )の作成
「Hierarchy欄 → 3D Object → Sphere」から、 Inspector欄で以下のように設定して下さい。


RollerAgent へ Rigidbody 追加
RollerAgent を選択した状態で、「Add Component」をクリックし 「Rigidbody」を追加して下さい

RollerAgent へ Behavior Parameters 追加
RollerAgent を選択した状態で、「Add Component」をクリックし 「Behavior Parameters」を追加後、以下のように設定して下さい。

RollerAgent へ C# script 追加
RollerAgent を選択した状態で、「Add Component」をクリックし 「New Script」を「RollerAgent」として追加後、 以下のように実装して下さい。
using System.Collections; using System.Collections.Generic; using UnityEngine; using Unity.MLAgents; using Unity.MLAgents.Sensors; using Unity.MLAgents.Actuators; public class RollerAgent : Agent { public Transform target; Rigidbody rBody; // 初期化時に呼ばれる public override void Initialize() { this.rBody = GetComponent<Rigidbody>(); } // エピソード開始時に呼ばれる public override void OnEpisodeBegin() { // RollerAgentが床から落下している時 if (this.transform.localPosition.y < 0) { // RollerAgentの位置と速度をリセット this.rBody.angularVelocity = Vector3.zero; this.rBody.velocity = Vector3.zero; this.transform.localPosition = new Vector3(0.0f, 0.5f, 0.0f); } // Targetの位置のリセット target.localPosition = new Vector3( Random.value * 8 - 4, 0.5f, Random.value * 8 - 4); } // 観察取得時に呼ばれる public override void CollectObservations(VectorSensor sensor) { sensor.AddObservation(target.localPosition); //TargetのXYZ座標 sensor.AddObservation(this.transform.localPosition); //RollerAgentのXYZ座標 sensor.AddObservation(rBody.velocity.x); // RollerAgentのX速度 sensor.AddObservation(rBody.velocity.z); // RollerAgentのZ速度 } // 行動実行時に呼ばれる public override void OnActionReceived(ActionBuffers actionBuffers) { // RollerAgentに力を加える Vector3 controlSignal = Vector3.zero; controlSignal.x = actionBuffers.ContinuousActions[0]; controlSignal.z = actionBuffers.ContinuousActions[1]; rBody.AddForce(controlSignal * 10); // RollerAgentがTargetの位置に到着した時 float distanceToTarget = Vector3.Distance( this.transform.localPosition, target.localPosition); if (distanceToTarget < 1.42f) { AddReward(1.0f); EndEpisode(); } // RollerAgentが床から落下した時 if (this.transform.localPosition.y < 0) { EndEpisode(); } } // ヒューリスティックモードの行動決定時に呼ばれる public override void Heuristic(in ActionBuffers actionsOut) { var continuousActionsOut = actionsOut.ContinuousActions; continuousActionsOut[0] = Input.GetAxis("Horizontal"); continuousActionsOut[1] = Input.GetAxis("Vertical"); } // // Start is called before the first frame update // void Start() // { // } // // Update is called once per frame // void Update() // { // } }
C# script の設定変更
先程の c# script実装後、inspector欄で以下のように設定して下さい

RollerAgent へ Decision Requester 追加
RollerAgent を選択した状態で、「Add Component」をクリックし 「Decision Requester」を追加後、以下のように設定して下さい

Behavior Parameters の設定変更
ここで、先程、追加した Behavior Parameters の設定変更を行います。
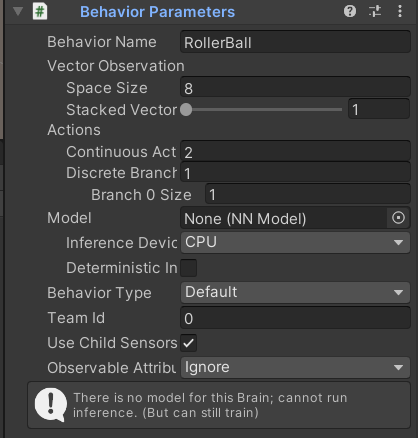
強化学習の実行
behaviors: RollerBall: trainer_type: ppo hyperparameters: batch_size: 10 buffer_size: 100 learning_rate: 0.0003 beta: 0.005 epsilon: 0.2 lambd: 0.95 num_epoch: 3 learning_rate_schedule: linear network_settings: normalize: true hidden_units: 128 num_layers: 2 vis_encode_type: simple reward_signals: extrinsic: gamma: 0.99 strength: 1.0 keep_checkpoints: 5 checkpoint_interval: 500000 max_steps: 500000 time_horizon: 64 summary_freq: 1000 threaded: true
上記のyamlを作成した上で、以下のコマンドを実行し、 その後、unityの再生ボタン(▶)をクリックすると、強化学習が開始されます。
学習開始後、ログが表示されますが、Mean Reward = 1.0 に達すると 十分ですので、Ctrl-Cで停止して下さい。
(ml_agents) C:\Users\end0t\tmp>mlagents-learn RollerBall.yaml
┐ ╖
╓╖╬|╡ ||╬╖╖
╓╖╬|||||┘ ╬|||||╬╖
╖╬|||||╬╜ ╙╬|||||╖╖ ╗╗╗
╬╬╬╬╖||╦╖ ╖╬||╗╣╣╣╬ ╟╣╣╬ ╟╣╣╣ ╜╜╜ ╟╣╣
╬╬╬╬╬╬╬╬╖|╬╖╖╓╬╪|╓╣╣╣╣╣╣╣╬ ╟╣╣╬ ╟╣╣╣ ╒╣╣╖╗╣╣╣╗ ╣╣╣ ╣╣╣╣╣╣ ╟╣╣╖ ╣╣╣
╬╬╬╬┐ ╙╬╬╬╬|╓╣╣╣╝╜ ╫╣╣╣╬ ╟╣╣╬ ╟╣╣╣ ╟╣╣╣╙ ╙╣╣╣ ╣╣╣ ╙╟╣╣╜╙ ╫╣╣ ╟╣╣
╬╬╬╬┐ ╙╬╬╣╣ ╫╣╣╣╬ ╟╣╣╬ ╟╣╣╣ ╟╣╣╬ ╣╣╣ ╣╣╣ ╟╣╣ ╣╣╣┌╣╣╜
╬╬╬╜ ╬╬╣╣ ╙╝╣╣╬ ╙╣╣╣╗╖╓╗╣╣╣╜ ╟╣╣╬ ╣╣╣ ╣╣╣ ╟╣╣╦╓ ╣╣╣╣╣
╙ ╓╦╖ ╬╬╣╣ ╓╗╗╖ ╙╝╣╣╣╣╝╜ ╘╝╝╜ ╝╝╝ ╝╝╝ ╙╣╣╣ ╟╣╣╣
╩╬╬╬╬╬╬╦╦╬╬╣╣╗╣╣╣╣╣╣╣╝ ╫╣╣╣╣
╙╬╬╬╬╬╬╬╣╣╣╣╣╣╝╜
╙╬╬╬╣╣╣╜
╙
Version information:
ml-agents: 0.28.0,
ml-agents-envs: 0.28.0,
Communicator API: 1.5.0,
PyTorch: 1.9.1+cu111
[INFO] Listening on port 5004. Start training by pressing the Play button in the Unity Editor.
[INFO] Connected to Unity environment with package version 2.2.1-exp.1 and communication version 1.5.0
[INFO] Connected new brain: RollerBall?team=0
[INFO] Hyperparameters for behavior name RollerBall:
trainer_type: ppo
hyperparameters:
batch_size: 10
buffer_size: 100
learning_rate: 0.0003
beta: 0.005
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: linear
beta_schedule: linear
epsilon_schedule: linear
network_settings:
normalize: True
hidden_units: 128
num_layers: 2
vis_encode_type: simple
memory: None
goal_conditioning_type: hyper
deterministic: False
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
network_settings:
normalize: False
hidden_units: 128
num_layers: 2
vis_encode_type: simple
memory: None
goal_conditioning_type: hyper
deterministic: False
init_path: None
keep_checkpoints: 5
checkpoint_interval: 500000
max_steps: 500000
time_horizon: 64
summary_freq: 1000
threaded: True
self_play: None
behavioral_cloning: None
[INFO] RollerBall. Step: 1000. Time Elapsed: 22.908 s. Mean Reward: 0.286. Std of Reward: 0.452. Training.
[INFO] RollerBall. Step: 2000. Time Elapsed: 35.768 s. Mean Reward: 0.294. Std of Reward: 0.456. Training.
<略>
[INFO] RollerBall. Step: 3000. Time Elapsed: 49.964 s. Mean Reward: 0.371. Std of Reward: 0.483. Training.
[INFO] RollerBall. Step: 26000. Time Elapsed: 469.437 s. Mean Reward: 0.992. Std of Reward: 0.089. Training.
[INFO] RollerBall. Step: 27000. Time Elapsed: 490.284 s. Mean Reward: 1.000. Std of Reward: 0.000. Training.
[INFO] RollerBall. Step: 28000. Time Elapsed: 510.507 s. Mean Reward: 0.985. Std of Reward: 0.122. Training.
[INFO] RollerBall. Step: 29000. Time Elapsed: 528.527 s. Mean Reward: 1.000. Std of Reward: 0.000. Training.
[INFO] RollerBall. Step: 30000. Time Elapsed: 546.339 s. Mean Reward: 0.993. Std of Reward: 0.086. Training.
[INFO] RollerBall. Step: 31000. Time Elapsed: 566.482 s. Mean Reward: 0.985. Std of Reward: 0.121. Training.
[INFO] RollerBall. Step: 32000. Time Elapsed: 589.243 s. Mean Reward: 1.000. Std of Reward: 0.000. Training.
[INFO] Learning was interrupted. Please wait while the graph is generated.
[INFO] Exported results\ppo\RollerBall\RollerBall-32329.onnx
[INFO] Copied results\ppo\RollerBall\RollerBall-32329.onnx to results\ppo\RollerBall.onnx.
(ml_agents) C:\Users\end0t\tmp>
学習結果の検証
先程の学習で、results フォルダが作成され、 その中に RollerBall.onnx が作成されますので、 これを unity の Assets にコピーし、 Behavior Parameters も設定して下さい。

最後に、unityの再生ボタン(▶)をクリックすると、 RollerAgentsが、Targetを追いかける様子を確認できます。