build & install llama.cpp to windows11 with gpu
C言語でのLLMランタイムである「Llama.cpp」を geforce rtx 4090 付の windows用に compile & install。
目次
- 参考url
- Visual Sudio or CUDA Toolkit の integration 修正
- build & install llama.cpp to windows11 with gpu
- 推論お試し実行
- gqaオプションは、LLaMAv2 70B用みたい
- 推論実行 - GPUはスカスカ、メモリやDISKはパンパン
参考url
- https://zenn.dev/fehde/articles/9f75cf56f25f4a
- https://note.com/npaka/n/n9eda56d3a463
- https://note.com/npaka/n/n0ad63134fbe2
Visual Sudio or CUDA Toolkit の integration 修正
linuxやmacでは、参考urlにある npakaさん の entry のように buildできると思いますが、今回の「windows11 with gpu」では 「cmake .. -DLLAMA_CUBLAS=ON」実行時に なぜか、cmakeがcudaを見つけられず、エラーが発生。
なので、参考url にある fehde さんの entry を参考にintegration 修正
ファイルコピー
DOS> cd c:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v11.2/extras/visual_studio_integration/MSBuildExtensions DOS> dir 2021/02/15 21:39 14,544 CUDA 11.2.props 2021/02/15 21:39 51,464 CUDA 11.2.targets 2021/02/15 21:39 32,298 CUDA 11.2.xml 2021/02/15 21:39 265,728 Nvda.Build.CudaTasks.v11.2.dll DOS> cp * c:/Program Files (x86)/Microsoft Visual Studio/2019/BuildTools/MSBuild/Microsoft/VC/v160/BuildCustomizations/
regedit
レジストリエディタを起動し、以下を追加
| 項目 | 内容 |
|---|---|
| レジストリキー | HKEY_LOCAL_MACHINE\SOFTWARE\NVIDIA Corporation\GPU Computing Toolkit\CUDA\v11.2 |
| 名前 | InstallDir |
| 種類 | REG_SZ (文字列) |
| データ | C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2 |

build & install llama.cpp to windows11 with gpu
DOS> git clone https://github.com/ggerganov/llama.cpp DOS> cd llama.cpp DOS> mkdir build DOS> cd build DOS> cmake .. -DLLAMA_CUBLAS=ON DOS> cmake --build . --config Release DOS> cd ..
↑こう実行すると、↓こちらのexe群がmakeされます。
DOS> cd C:\Users\end0t\tmp\llama.cpp DOS> dir build\bin\Release 2023/08/20 20:15 <DIR> . 2023/08/20 20:14 <DIR> .. 2023/08/20 20:14 4,195,840 baby-llama.exe 2023/08/20 20:14 4,135,936 benchmark.exe 2023/08/20 20:14 4,049,920 convert-llama2c-to-ggml.exe 2023/08/20 20:14 4,366,336 embd-input-test.exe 2023/08/20 20:14 4,339,200 embedding.exe 2023/08/20 20:14 4,342,272 llama-bench.exe 2023/08/20 20:15 4,423,168 main.exe 2023/08/20 20:15 4,350,464 perplexity.exe 2023/08/20 20:15 3,969,536 q8dot.exe 2023/08/20 20:15 4,093,440 quantize-stats.exe 2023/08/20 20:15 4,025,856 quantize.exe 2023/08/20 20:15 4,332,544 save-load-state.exe 2023/08/20 20:15 4,771,328 server.exe 2023/08/20 20:15 4,242,432 simple.exe 2023/08/20 20:15 4,168,704 test-grad0.exe 2023/08/20 20:15 40,960 test-grammar-parser.exe 2023/08/20 20:15 3,991,552 test-llama-grammar.exe 2023/08/20 20:15 3,971,072 test-quantize-fns.exe 2023/08/20 20:15 3,983,360 test-quantize-perf.exe 2023/08/20 20:15 3,992,576 test-sampling.exe 2023/08/20 20:15 4,039,168 test-tokenizer-0.exe 2023/08/20 20:15 4,346,880 train-text-from-scratch.exe 2023/08/20 20:15 3,974,144 vdot.exe
推論お試し実行
npakaさんのentryを参考に、推論を実行してみます。
(mycuda) C:\Users\end0t\tmp\llama.cpp>build\bin\Release\main.exe \ -m ../llama_model/llama-2-70b-chat.ggmlv3.q4_K_M.bin \ -gqa 8 --temp 0.1 \ -p "### Instruction: What is the height of Mount Fuji? ### Response:" \ -ngl 32 -b 512 main: build = 1007 (1f0bccb) main: seed = 1692530627 ggml_init_cublas: found 1 CUDA devices: Device 0: NVIDIA GeForce RTX 4090, compute capability 8.9 llama.cpp: loading model from ../llama_model/llama-2-70b-chat.ggmlv3.q4_K_M.bin llama_model_load_internal: warning: assuming 70B model based on GQA == 8 llama_model_load_internal: format = ggjt v3 (latest) llama_model_load_internal: n_vocab = 32000 llama_model_load_internal: n_ctx = 512 llama_model_load_internal: n_embd = 8192 llama_model_load_internal: n_mult = 4096 llama_model_load_internal: n_head = 64 llama_model_load_internal: n_head_kv = 8 llama_model_load_internal: n_layer = 80 llama_model_load_internal: n_rot = 128 llama_model_load_internal: n_gqa = 8 llama_model_load_internal: rnorm_eps = 5.0e-06 llama_model_load_internal: n_ff = 28672 llama_model_load_internal: freq_base = 10000.0 llama_model_load_internal: freq_scale = 1 llama_model_load_internal: ftype = 15 (mostly Q4_K - Medium) llama_model_load_internal: model size = 70B llama_model_load_internal: ggml ctx size = 0.21 MB llama_model_load_internal: using CUDA for GPU acceleration llama_model_load_internal: mem required = 24261.83 MB (+ 160.00 MB per state) llama_model_load_internal: allocating batch_size x (1280 kB + n_ctx x 256 B) = 704 MB VRAM for the scratch buffer llama_model_load_internal: offloading 32 repeating layers to GPU llama_model_load_internal: offloaded 32/83 layers to GPU llama_model_load_internal: total VRAM used: 16471 MB llama_new_context_with_model: kv self size = 160.00 MB system_info: n_threads = 4 / 8 | AVX = 1 | AVX2 = 1 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 1 | VSX = 0 | sampling: repeat_last_n = 64, repeat_penalty = 1.100000, presence_penalty = 0.000000, frequency_penalty = 0.000000, top_k = 40, tfs_z = 1.000000, top_p = 0.950000, typical_p = 1.000000, temp = 0.100000, mirostat = 0, mirostat_lr = 0.100000, mirostat_ent = 5.000000 generate: n_ctx = 512, n_batch = 512, n_predict = -1, n_keep = 0 ### Instruction: What is the height of Mount Fuji? ### Response: The height of Mount Fuji is 3,776 meters (12,388 feet) above sea level.
gqaオプションは、LLaMAv2 70B用みたい
DOS> build\bin\Release\main.exe --help <略> -gqa N, --gqa N grouped-query attention factor (TEMP!!! use 8 for LLaMAv2 70B) (default: 1)
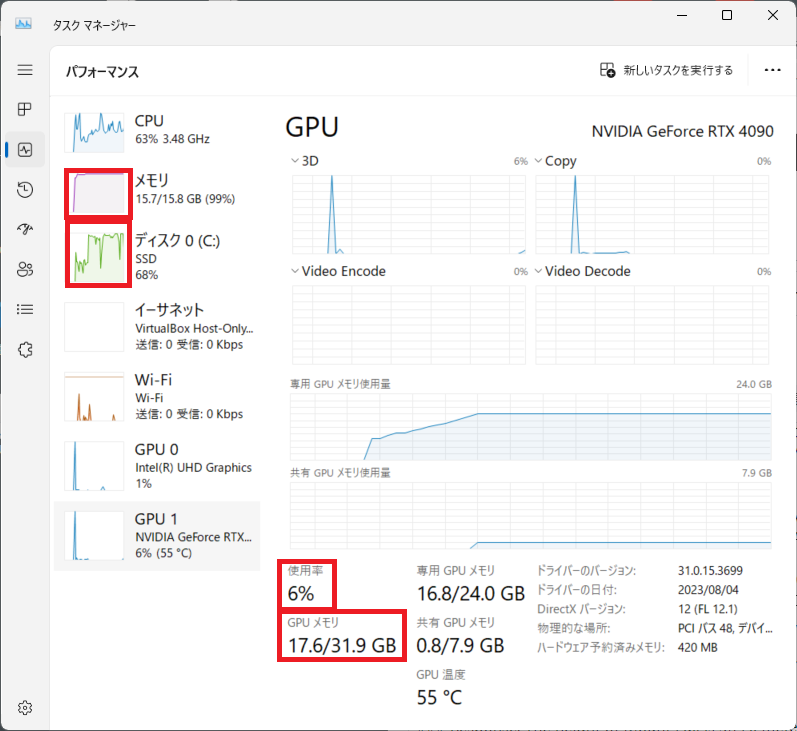
推論実行 - GPUはスカスカ、メモリやDISKはパンパン
推論実行時のタスクマネージャの画面が以下。
GPUはgeforce rtx 4090ですので、余裕があるようですが、 PC本体に余裕がないようです...