GitHub - oreilly-japan/deep-learning-from-scratch: 『ゼロから作る Deep Learning』(O'Reilly Japan, 2016)
「ゼロから作るDeep Learning ① (Pythonで学ぶディープラーニングの理論と実装)」 p.112~121 の写経です。
また、以下のキカガクのページも分かりやすいかと思います。
https://free.kikagaku.ai/tutorial/basic_of_deep_learning/learn/neural_network_basic_backward
目次
python
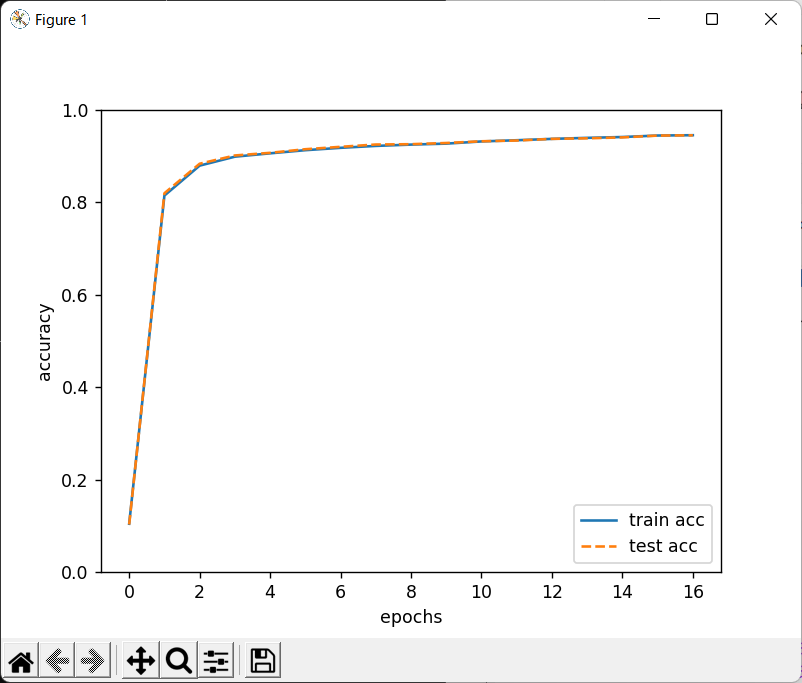
# coding: utf-8 import gzip import matplotlib.pyplot as plt import numpy as np import os import sys import urllib.request def main(): # MNISTデータのdownload mymnist = MyMnist() (x_train, t_train, x_test, t_test) = mymnist.load_mnist() iters_num = 10000 # 繰り返し回数 batch_size = 100 learning_rate = 0.1 # 学習率 η train_size = x_train.shape[0] iter_per_epoch = max(train_size / batch_size, 1) train_loss_list = [] train_acc_list = [] test_acc_list = [] # 2層ニューラルネットワークでの訓練 network = TwoLayerNet(28*28, 100, 10) # for param_type in ['W1','b1','W2','b2',]: # print( param_type, network.params[param_type].shape ) for i in range(iters_num): batch_mask = np.random.choice(train_size, batch_size) x_batch = x_train[batch_mask] t_batch = t_train[batch_mask] # 勾配を計算し、パラメータを更新 #grad = network.numerical_gradient(x_batch, t_batch) grad = network.gradient(x_batch, t_batch) for key in ('W1', 'b1', 'W2', 'b2'): network.params[key] -= learning_rate * grad[key] loss = network.loss(x_batch, t_batch) train_loss_list.append(loss) if i % iter_per_epoch == 0: train_acc = network.accuracy(x_train, t_train) test_acc = network.accuracy(x_test, t_test) train_acc_list.append(train_acc) test_acc_list.append(test_acc) print("train acc, test acc | " + str(train_acc) + \ ", " + str(test_acc)) my_plot = MyPlot() my_plot.disp_graph(train_acc_list,test_acc_list) class MyMnist: def __init__(self): pass def load_mnist(self): data_files = self.download_mnist() # convert numpy dataset = {} dataset['train_img'] = self.load_img( data_files['train_img'] ) dataset['train_label'] = self.load_label(data_files['train_label']) dataset['test_img'] = self.load_img( data_files['test_img'] ) dataset['test_label'] = self.load_label(data_files['test_label']) for key in ('train_img', 'test_img'): dataset[key] = dataset[key].astype(np.float32) dataset[key] /= 255.0 for key in ('train_label','test_label'): dataset[key]=self.change_one_hot_label( dataset[key] ) return (dataset['train_img'], dataset['train_label'], dataset['test_img'], dataset['test_label'] ) def change_one_hot_label(self,X): T = np.zeros((X.size, 10)) for idx, row in enumerate(T): row[X[idx]] = 1 return T def download_mnist(self): url_base = 'http://yann.lecun.com/exdb/mnist/' key_file = {'train_img' :'train-images-idx3-ubyte.gz', 'train_label':'train-labels-idx1-ubyte.gz', 'test_img' :'t10k-images-idx3-ubyte.gz', 'test_label' :'t10k-labels-idx1-ubyte.gz' } data_files = {} dataset_dir = os.path.dirname(os.path.abspath(__file__)) for data_name, file_name in key_file.items(): req_url = url_base+file_name file_path = dataset_dir + "/" + file_name request = urllib.request.Request( req_url ) response = urllib.request.urlopen(request).read() with open(file_path, mode='wb') as f: f.write(response) data_files[data_name] = file_path return data_files def load_img( self,file_path): img_size = 784 # = 28*28 with gzip.open(file_path, 'rb') as f: data = np.frombuffer(f.read(), np.uint8, offset=16) data = data.reshape(-1, img_size) return data def load_label(self,file_path): with gzip.open(file_path, 'rb') as f: labels = np.frombuffer(f.read(), np.uint8, offset=8) return labels class MyPlot: def __init__(self): pass def disp_graph(self,train_acc_list,test_acc_list): markers = {'train': 'o', 'test': 's'} x = np.arange(len(train_acc_list)) plt.plot(x, train_acc_list, label='train acc') plt.plot(x, test_acc_list, label='test acc', linestyle='--') plt.xlabel("epochs") plt.ylabel("accuracy") plt.ylim(0, 1.0) plt.legend(loc='lower right') plt.show() class TwoLayerNet: def __init__(self, input_size, # 入力層のneuron数 hidden_size, # 隠れ層の〃 output_size, # 出力層の〃 weight_init_std=0.01): # 重みの初期化 self.params = {} self.params['W1'] = \ weight_init_std * np.random.randn(input_size, hidden_size) self.params['b1'] = np.zeros(hidden_size) self.params['W2'] = \ weight_init_std * np.random.randn(hidden_size, output_size) self.params['b2'] = np.zeros(output_size) def predict(self, x): W1, W2 = self.params['W1'], self.params['W2'] b1, b2 = self.params['b1'], self.params['b2'] a1 = np.dot(x, W1) + b1 z1 = self.sigmoid(a1) a2 = np.dot(z1, W2) + b2 y = self.softmax(a2) return y # x:入力データ, t:教師データ def loss(self, x, t): y = self.predict(x) return self.cross_entropy_error(y, t) def accuracy(self, x, t): y = self.predict(x) y = np.argmax(y, axis=1) t = np.argmax(t, axis=1) accuracy = np.sum(y == t) / float(x.shape[0]) return accuracy # x:入力データ, t:教師データ def numerical_gradient(self, x, t): loss_W = lambda W: self.loss(x, t) grads = {} grads['W1'] = self._numerical_gradient(loss_W, self.params['W1']) grads['b1'] = self._numerical_gradient(loss_W, self.params['b1']) grads['W2'] = self._numerical_gradient(loss_W, self.params['W2']) grads['b2'] = self._numerical_gradient(loss_W, self.params['b2']) return grads def _numerical_gradient(self, f, x): h = 1e-4 # 0.0001 grad = np.zeros_like(x) it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite']) while not it.finished: idx = it.multi_index tmp_val = x[idx] x[idx] = tmp_val + h fxh1 = f(x) # f(x+h) x[idx] = tmp_val - h fxh2 = f(x) # f(x-h) grad[idx] = (fxh1 - fxh2) / (2*h) x[idx] = tmp_val # 値を元に戻す it.iternext() return grad def gradient(self, x, t): W1, W2 = self.params['W1'], self.params['W2'] b1, b2 = self.params['b1'], self.params['b2'] grads = {} batch_num = x.shape[0] # forward a1 = np.dot(x, W1) + b1 z1 = self.sigmoid(a1) a2 = np.dot(z1, W2) + b2 y = self.softmax(a2) # backward dy = (y - t) / batch_num grads['W2'] = np.dot(z1.T, dy) grads['b2'] = np.sum(dy, axis=0) dz1 = np.dot(dy, W2.T) da1 = self.sigmoid_grad(a1) * dz1 grads['W1'] = np.dot(x.T, da1) grads['b1'] = np.sum(da1, axis=0) return grads def sigmoid(self,x): return 1 / (1 + np.exp(-x)) def sigmoid_grad(self,x): return (1.0 - self.sigmoid(x)) * self.sigmoid(x) def cross_entropy_error(self, y, t): if y.ndim == 1: t = t.reshape(1, t.size) y = y.reshape(1, y.size) # 教師データがone-hot-vectorの場合、正解ラベルのインデックスに変換 if t.size == y.size: t = t.argmax(axis=1) batch_size = y.shape[0] return -np.sum(np.log(y[np.arange(batch_size),t]+ 1e-7))/batch_size def softmax(self,x): x = x - np.max(x, axis=-1, keepdims=True) # オーバーフロー対策 return np.exp(x) / np.sum(np.exp(x), axis=-1, keepdims=True) if __name__ == '__main__': main()
実行結果
(dl_scratch) C:\Users\end0t\tmp\deep-learning-from-scratch\ch04>python foo.py train acc, test acc | 0.0993, 0.1032 train acc, test acc | 0.8140666666666667, 0.8168 train acc, test acc | 0.8824, 0.8873 train acc, test acc | 0.8999166666666667, 0.9047 train acc, test acc | 0.9076333333333333, 0.9121 train acc, test acc | 0.9124, 0.9162 train acc, test acc | 0.9184166666666667, 0.9219 train acc, test acc | 0.9225333333333333, 0.9231 train acc, test acc | 0.92515, 0.9279 train acc, test acc | 0.9284166666666667, 0.9299 train acc, test acc | 0.9318833333333333, 0.9321 train acc, test acc | 0.9342333333333334, 0.9346 train acc, test acc | 0.9367, 0.9374 train acc, test acc | 0.93965, 0.9399 train acc, test acc | 0.9422, 0.9412 train acc, test acc | 0.9439166666666666, 0.9423 train acc, test acc | 0.9461333333333334, 0.9441