deep-learning-from-scratch/ch06 at master · oreilly-japan/deep-learning-from-scratch · GitHub
「ゼロから作るDeep Learning ① (Pythonで学ぶディープラーニングの理論と実装)」 p.193~195 の写経です。
先程の Weight decay (荷重減衰)とは別に Dropoutという過学習軽減方法もあるようです。
Dropoutでは、以下のようにランダムにneuronを消去しながら学習を行うことで 過学習を回避します。 (アンサンブル学習やランダムフォレストと似た考え方のようです)
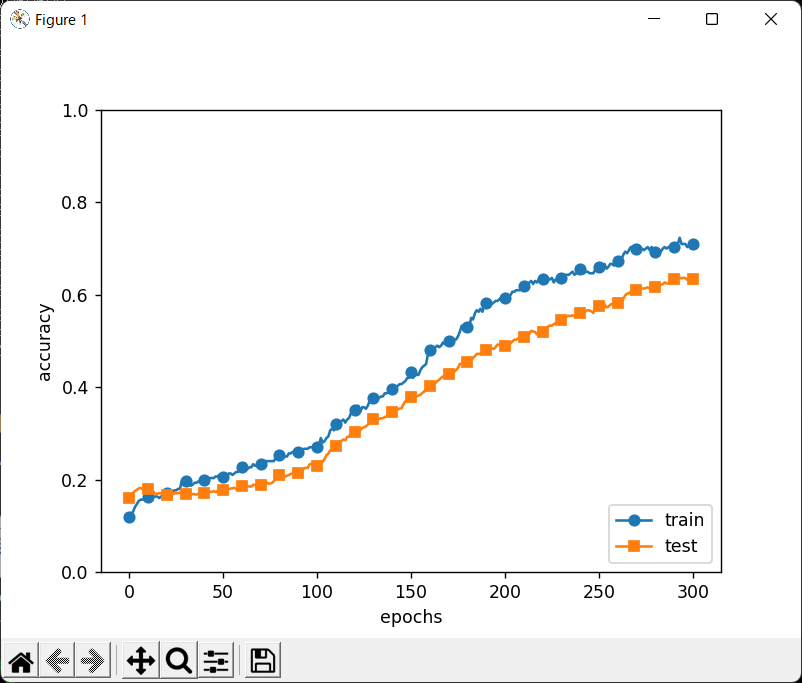
# coding: utf-8 import os import numpy as np import matplotlib.pyplot as plt from collections import OrderedDict import urllib.request import gzip from common.optimizer import * def main(): mymnist = MyMnist() (x_train, t_train, x_test, t_test) = mymnist.load_mnist() # 過学習を再現するために、学習データを削減 x_train = x_train[:300] t_train = t_train[:300] network = MultiLayerNetExtend(input_size =784, hidden_size_list=[100,100,100,100,100,100], output_size =10, use_dropout =True, dropout_ration=0.2 ) trainer = Trainer(network, x_train, t_train, x_test, t_test, epochs=301, mini_batch_size=100, optimizer='sgd', optimizer_param={'lr': 0.01}, verbose=True) trainer.train() train_acc_list, test_acc_list = trainer.train_acc_list, trainer.test_acc_list # グラフの描画========== markers = {'train': 'o', 'test': 's'} x = np.arange(len(train_acc_list)) plt.plot(x, train_acc_list, marker='o', label='train', markevery=10) plt.plot(x, test_acc_list, marker='s', label='test', markevery=10) plt.xlabel("epochs") plt.ylabel("accuracy") plt.ylim(0, 1.0) plt.legend(loc='lower right') plt.show() class MyMnist: def __init__(self): pass def load_mnist(self): data_files = self.download_mnist() # convert numpy dataset = {} dataset['train_img'] = self.load_img( data_files['train_img'] ) dataset['train_label'] = self.load_label(data_files['train_label']) dataset['test_img'] = self.load_img( data_files['test_img'] ) dataset['test_label'] = self.load_label(data_files['test_label']) for key in ('train_img', 'test_img'): dataset[key] = dataset[key].astype(np.float32) dataset[key] /= 255.0 for key in ('train_label','test_label'): dataset[key]=self.change_one_hot_label( dataset[key] ) return (dataset['train_img'], dataset['train_label'], dataset['test_img'], dataset['test_label'] ) def change_one_hot_label(self,X): T = np.zeros((X.size, 10)) for idx, row in enumerate(T): row[X[idx]] = 1 return T def download_mnist(self): url_base = 'http://yann.lecun.com/exdb/mnist/' key_file = {'train_img' :'train-images-idx3-ubyte.gz', 'train_label':'train-labels-idx1-ubyte.gz', 'test_img' :'t10k-images-idx3-ubyte.gz', 'test_label' :'t10k-labels-idx1-ubyte.gz' } data_files = {} dataset_dir = os.path.dirname(os.path.abspath(__file__)) for data_name, file_name in key_file.items(): req_url = url_base+file_name file_path = dataset_dir + "/" + file_name request = urllib.request.Request( req_url ) response = urllib.request.urlopen(request).read() with open(file_path, mode='wb') as f: f.write(response) data_files[data_name] = file_path return data_files def load_img( self,file_path): img_size = 784 # = 28*28 with gzip.open(file_path, 'rb') as f: data = np.frombuffer(f.read(), np.uint8, offset=16) data = data.reshape(-1, img_size) return data def load_label(self,file_path): with gzip.open(file_path, 'rb') as f: labels = np.frombuffer(f.read(), np.uint8, offset=8) return labels # 拡張版の全結合による多層ニューラルネットワーク # (Weiht Decay、Dropout、Batch Normalizationの機能を持つ) class MultiLayerNetExtend: def __init__( self, input_size, # 入力size (MNISTの場合 784) hidden_size_list, # 隠れ層のneuron数list 例[100,100,100] output_size, # 出力size (MNISTの場合 10) activation='relu', # 活性化関数 relu sigmoid weight_init_std='relu',# ※ weight_decay_lambda=0, # Weight Decay(L2ノルム)の強さ use_dropout = False, dropout_ration = 0.5, # Dropoutの割り合い use_batchnorm=False ): # ※ weight_init_std : 重みの標準偏差を指定(例0.01) # relu or he →Heの初期値 # sigmoid or xavier →Xavierの初期値 self.input_size = input_size self.output_size = output_size self.hidden_size_list = hidden_size_list self.hidden_layer_num = len(hidden_size_list) self.use_dropout = use_dropout self.weight_decay_lambda = weight_decay_lambda self.use_batchnorm = use_batchnorm self.params = {} # 重みの初期化 self.__init_weight(weight_init_std) # レイヤの生成 activation_layer = {'sigmoid': Sigmoid, 'relu': Relu} self.layers = OrderedDict() for idx in range(1, self.hidden_layer_num+1): self.layers['Affine' + str(idx)] = Affine(self.params['W' + str(idx)], self.params['b' + str(idx)]) if self.use_batchnorm: self.params['gamma' + str(idx)] = np.ones(hidden_size_list[idx-1]) self.params['beta' + str(idx)] = np.zeros(hidden_size_list[idx-1]) self.layers['BatchNorm' + str(idx)] = \ BatchNormalization(self.params['gamma' + str(idx)], self.params['beta' + str(idx)] ) self.layers['Activation_function' + str(idx)] = \ activation_layer[activation]() if self.use_dropout: self.layers['Dropout' + str(idx)] = Dropout(dropout_ration) idx = self.hidden_layer_num + 1 self.layers['Affine' + str(idx)] = Affine(self.params['W' + str(idx)], self.params['b' + str(idx)]) self.last_layer = SoftmaxWithLoss() def __init_weight(self, weight_init_std): """重みの初期値設定 Parameters ---------- weight_init_std : 重みの標準偏差を指定(e.g. 0.01) 'relu'または'he'を指定した場合は「Heの初期値」を設定 'sigmoid'または'xavier'を指定した場合は「Xavierの初期値」を設定 """ all_size_list = [self.input_size] + self.hidden_size_list + [self.output_size] for idx in range(1, len(all_size_list)): scale = weight_init_std if str(weight_init_std).lower() in ('relu', 'he'): scale = np.sqrt(2.0 / all_size_list[idx - 1]) # ReLUを使う場合に推奨される初期値 elif str(weight_init_std).lower() in ('sigmoid', 'xavier'): scale = np.sqrt(1.0 / all_size_list[idx - 1]) # sigmoidを使う場合に推奨される初期値 self.params['W' + str(idx)] = scale * np.random.randn(all_size_list[idx-1], all_size_list[idx]) self.params['b' + str(idx)] = np.zeros(all_size_list[idx]) def predict(self, x, train_flg=False): for key, layer in self.layers.items(): if "Dropout" in key or "BatchNorm" in key: x = layer.forward(x, train_flg) else: x = layer.forward(x) return x def loss(self, x, t, train_flg=False): """損失関数を求める 引数のxは入力データ、tは教師ラベル """ y = self.predict(x, train_flg) weight_decay = 0 for idx in range(1, self.hidden_layer_num + 2): W = self.params['W' + str(idx)] weight_decay += 0.5 * self.weight_decay_lambda * np.sum(W**2) return self.last_layer.forward(y, t) + weight_decay def accuracy(self, x, t): y = self.predict(x, train_flg=False) y = np.argmax(y, axis=1) if t.ndim != 1 : t = np.argmax(t, axis=1) accuracy = np.sum(y == t) / float(x.shape[0]) return accuracy def numerical_gradient(self, x, t): """勾配を求める(数値微分) Parameters ---------- x : 入力データ t : 教師ラベル Returns ------- 各層の勾配を持ったディクショナリ変数 grads['W1']、grads['W2']、...は各層の重み grads['b1']、grads['b2']、...は各層のバイアス """ loss_W = lambda W: self.loss(x, t, train_flg=True) grads = {} for idx in range(1, self.hidden_layer_num+2): grads['W' + str(idx)] = numerical_gradient(loss_W, self.params['W' + str(idx)]) grads['b' + str(idx)] = numerical_gradient(loss_W, self.params['b' + str(idx)]) if self.use_batchnorm and idx != self.hidden_layer_num+1: grads['gamma' + str(idx)] = numerical_gradient(loss_W, self.params['gamma' + str(idx)]) grads['beta' + str(idx)] = numerical_gradient(loss_W, self.params['beta' + str(idx)]) return grads def gradient(self, x, t): # forward self.loss(x, t, train_flg=True) # backward dout = 1 dout = self.last_layer.backward(dout) layers = list(self.layers.values()) layers.reverse() for layer in layers: dout = layer.backward(dout) # 設定 grads = {} for idx in range(1, self.hidden_layer_num+2): grads['W' + str(idx)] = self.layers['Affine' + str(idx)].dW + self.weight_decay_lambda * self.params['W' + str(idx)] grads['b' + str(idx)] = self.layers['Affine' + str(idx)].db if self.use_batchnorm and idx != self.hidden_layer_num+1: grads['gamma' + str(idx)] = self.layers['BatchNorm' + str(idx)].dgamma grads['beta' + str(idx)] = self.layers['BatchNorm' + str(idx)].dbeta return grads class Affine: def __init__(self, W, b): self.W =W self.b = b self.x = None self.original_x_shape = None # 重み・バイアスパラメータの微分 self.dW = None self.db = None def forward(self, x): # テンソル対応 self.original_x_shape = x.shape x = x.reshape(x.shape[0], -1) self.x = x out = np.dot(self.x, self.W) + self.b return out def backward(self, dout): dx = np.dot(dout, self.W.T) self.dW = np.dot(self.x.T, dout) self.db = np.sum(dout, axis=0) dx = dx.reshape(*self.original_x_shape) return dx class Relu: def __init__(self): self.mask = None def forward(self, x): self.mask = (x <= 0) out = x.copy() out[self.mask] = 0 return out def backward(self, dout): dout[self.mask] = 0 dx = dout return dx class Sigmoid: def __init__(self): self.out = None def forward(self, x): out = sigmoid(x) self.out = out return out def backward(self, dout): dx = dout * (1.0 - self.out) * self.out return dx # http://arxiv.org/abs/1502.03167 class BatchNormalization: def __init__(self, gamma, beta, momentum=0.9, running_mean=None, running_var=None): self.gamma = gamma self.beta = beta self.momentum = momentum self.input_shape = None # Conv層の場合は4次元、全結合層の場合は2次元 # テスト時に使用する平均と分散 self.running_mean = running_mean self.running_var = running_var # backward時に使用する中間データ self.batch_size = None self.xc = None self.std = None self.dgamma = None self.dbeta = None def forward(self, x, train_flg=True): self.input_shape = x.shape if x.ndim != 2: N, C, H, W = x.shape x = x.reshape(N, -1) out = self.__forward(x, train_flg) return out.reshape(*self.input_shape) def __forward(self, x, train_flg): if self.running_mean is None: N, D = x.shape self.running_mean = np.zeros(D) self.running_var = np.zeros(D) if train_flg: mu = x.mean(axis=0) xc = x - mu var = np.mean(xc**2, axis=0) std = np.sqrt(var + 10e-7) xn = xc / std self.batch_size = x.shape[0] self.xc = xc self.xn = xn self.std = std self.running_mean = \ self.momentum * self.running_mean + (1-self.momentum) * mu self.running_var = \ self.momentum * self.running_var + (1-self.momentum) * var else: xc = x - self.running_mean xn = xc / ((np.sqrt(self.running_var + 10e-7))) out = self.gamma * xn + self.beta return out def backward(self, dout): if dout.ndim != 2: N, C, H, W = dout.shape dout = dout.reshape(N, -1) dx = self.__backward(dout) dx = dx.reshape(*self.input_shape) return dx def __backward(self, dout): dbeta = dout.sum(axis=0) dgamma = np.sum(self.xn * dout, axis=0) dxn = self.gamma * dout dxc = dxn / self.std dstd = -np.sum((dxn * self.xc) / (self.std * self.std), axis=0) dvar = 0.5 * dstd / self.std dxc += (2.0 / self.batch_size) * self.xc * dvar dmu = np.sum(dxc, axis=0) dx = dxc - dmu / self.batch_size self.dgamma = dgamma self.dbeta = dbeta return dx # http://arxiv.org/abs/1207.0580 class Dropout: def __init__(self, dropout_ratio=0.5): self.dropout_ratio = dropout_ratio self.mask = None def forward(self, x, train_flg=True): if train_flg: self.mask = np.random.rand(*x.shape) > self.dropout_ratio return x * self.mask else: return x * (1.0 - self.dropout_ratio) def backward(self, dout): return dout * self.mask class SoftmaxWithLoss: def __init__(self): self.loss = None self.y = None # softmaxの出力 self.t = None # 教師データ def forward(self, x, t): self.t = t self.y = self.softmax(x) self.loss = self.cross_entropy_error(self.y, self.t) return self.loss def backward(self, dout=1): batch_size = self.t.shape[0] if self.t.size == self.y.size: # 教師データがone-hot-vectorの場合 dx = (self.y - self.t) / batch_size else: dx = self.y.copy() dx[np.arange(batch_size), self.t] -= 1 dx = dx / batch_size return dx def softmax(self, x): x = x - np.max(x, axis=-1, keepdims=True) # オーバーフロー対策 return np.exp(x) / np.sum(np.exp(x), axis=-1, keepdims=True) def cross_entropy_error(self, y, t): if y.ndim == 1: t = t.reshape(1, t.size) y = y.reshape(1, y.size) # 教師データがone-hot-vectorの場合、正解ラベルのインデックスに変換 if t.size == y.size: t = t.argmax(axis=1) batch_size = y.shape[0] return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size class Trainer: def __init__(self, network, x_train, t_train, x_test, t_test, epochs=20, mini_batch_size=100, optimizer='SGD', optimizer_param={'lr':0.01}, evaluate_sample_num_per_epoch=None, verbose=True): self.network = network self.verbose = verbose self.x_train = x_train self.t_train = t_train self.x_test = x_test self.t_test = t_test self.epochs = epochs self.batch_size = mini_batch_size self.evaluate_sample_num_per_epoch = evaluate_sample_num_per_epoch # optimizer optimizer_class_dict = {'sgd' :SGD, 'momentum':Momentum, 'nesterov':Nesterov, 'adagrad' :AdaGrad, 'rmsprop' :RMSprop, 'adam' :Adam} self.optimizer = optimizer_class_dict[optimizer.lower()](**optimizer_param) self.train_size = x_train.shape[0] self.iter_per_epoch = max(self.train_size / mini_batch_size, 1) self.max_iter = int(epochs * self.iter_per_epoch) self.current_iter = 0 self.current_epoch = 0 self.train_loss_list = [] self.train_acc_list = [] self.test_acc_list = [] def train_step(self): batch_mask = np.random.choice(self.train_size, self.batch_size) x_batch = self.x_train[batch_mask] t_batch = self.t_train[batch_mask] grads = self.network.gradient(x_batch, t_batch) self.optimizer.update(self.network.params, grads) loss = self.network.loss(x_batch, t_batch) self.train_loss_list.append(loss) if self.verbose: print("train loss:" + str(loss)) if self.current_iter % self.iter_per_epoch == 0: self.current_epoch += 1 x_train_sample, t_train_sample = self.x_train, self.t_train x_test_sample, t_test_sample = self.x_test, self.t_test if not self.evaluate_sample_num_per_epoch is None: t = self.evaluate_sample_num_per_epoch x_train_sample, t_train_sample = self.x_train[:t], self.t_train[:t] x_test_sample, t_test_sample = self.x_test[:t], self.t_test[:t] train_acc = self.network.accuracy(x_train_sample, t_train_sample) test_acc = self.network.accuracy(x_test_sample, t_test_sample) self.train_acc_list.append(train_acc) self.test_acc_list.append(test_acc) if self.verbose: print("epoch:",str(self.current_epoch), "train acc:",str(train_acc), "test acc:", str(test_acc) ) self.current_iter += 1 def train(self): for i in range(self.max_iter): self.train_step() test_acc = self.network.accuracy(self.x_test, self.t_test) if self.verbose: print("=============== Final Test Accuracy ===============") print("test acc:" + str(test_acc)) # 確率的勾配降下法(Stochastic Gradient Descent) class SGD: def __init__(self, lr=0.01): self.lr = lr def update(self, params, grads): for key in params.keys(): params[key] -= self.lr * grads[key] class Momentum: def __init__(self, lr=0.01, momentum=0.9): self.lr = lr self.momentum = momentum self.v = None def update(self, params, grads): if self.v is None: self.v = {} for key, val in params.items(): self.v[key] = np.zeros_like(val) for key in params.keys(): self.v[key] = self.momentum*self.v[key] - self.lr*grads[key] params[key] += self.v[key] # Nesterov's Accelerated Gradient http://arxiv.org/abs/1212.0901 class Nesterov: def __init__(self, lr=0.01, momentum=0.9): self.lr = lr self.momentum = momentum self.v = None def update(self, params, grads): if self.v is None: self.v = {} for key, val in params.items(): self.v[key] = np.zeros_like(val) for key in params.keys(): params[key] += self.momentum * self.momentum * self.v[key] params[key] -= (1 + self.momentum) * self.lr * grads[key] self.v[key] *= self.momentum self.v[key] -= self.lr * grads[key] class AdaGrad: def __init__(self, lr=0.01): self.lr = lr self.h = None def update(self, params, grads): if self.h is None: self.h = {} for key, val in params.items(): self.h[key] = np.zeros_like(val) for key in params.keys(): self.h[key] += grads[key] * grads[key] params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7) class RMSprop: def __init__(self, lr=0.01, decay_rate = 0.99): self.lr = lr self.decay_rate = decay_rate self.h = None def update(self, params, grads): if self.h is None: self.h = {} for key, val in params.items(): self.h[key] = np.zeros_like(val) for key in params.keys(): self.h[key] *= self.decay_rate self.h[key] += (1 - self.decay_rate) * grads[key] * grads[key] params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7) class Adam: # http://arxiv.org/abs/1412.6980v8 def __init__(self, lr=0.001, beta1=0.9, beta2=0.999): self.lr = lr self.beta1 = beta1 self.beta2 = beta2 self.iter = 0 self.m = None self.v = None def update(self, params, grads): if self.m is None: self.m, self.v = {}, {} for key, val in params.items(): self.m[key] = np.zeros_like(val) self.v[key] = np.zeros_like(val) self.iter += 1 lr_t = self.lr * np.sqrt(1.0 - self.beta2**self.iter) / \ (1.0 - self.beta1**self.iter) for key in params.keys(): #self.m[key] = self.beta1*self.m[key] + (1-self.beta1)*grads[key] #self.v[key] = self.beta2*self.v[key] + (1-self.beta2)*(grads[key]**2) self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key]) self.v[key] += (1 - self.beta2) * (grads[key]**2 - self.v[key]) params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7) #unbias_m += (1 - self.beta1) * (grads[key] - self.m[key]) # correct bias #unbisa_b += (1 - self.beta2) * (grads[key]*grads[key] - self.v[key]) # correct bias #params[key] += self.lr * unbias_m / (np.sqrt(unbisa_b) + 1e-7) if __name__ == '__main__': main()
↑こう書くと、↓こう表示され、 先程のentry同様、精度+100%に達していないことから、 過学習となっていないことが分かります。